VVision-Language-Action (VLA) models enable robots to follow natural language instructions and generalize across diverse tasks, but they remain vulnerable to execution failures that compromise reliability in real-world deployment.
Detecting such failures during execution is therefore critical for the robust deployment of embodied systems.
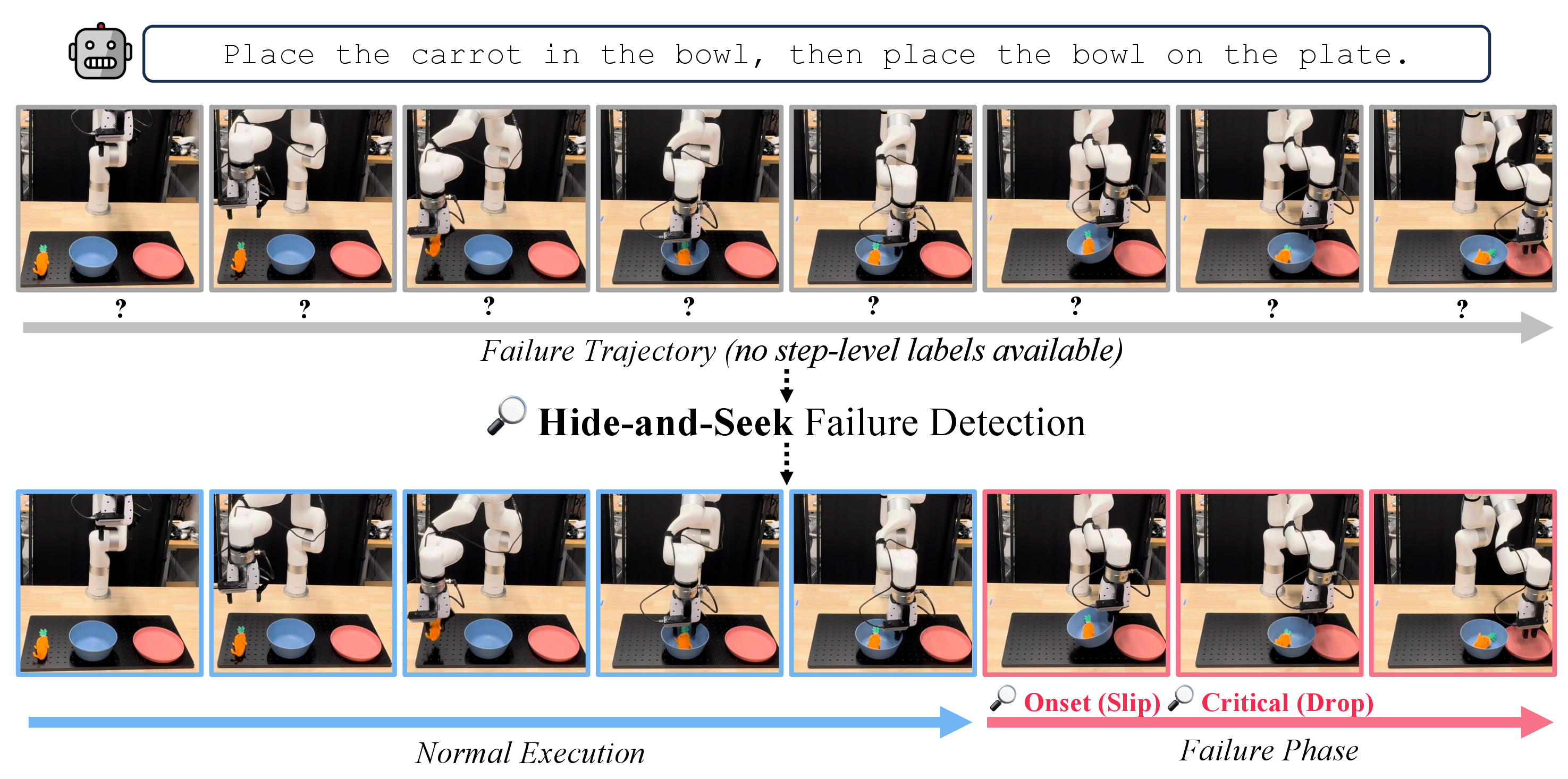
Existing failure detection methods either rely on expensive action resampling or external models, while alternatives propagate trajectory-level labels uniformly across every timestep, obscuring localized failure signals.
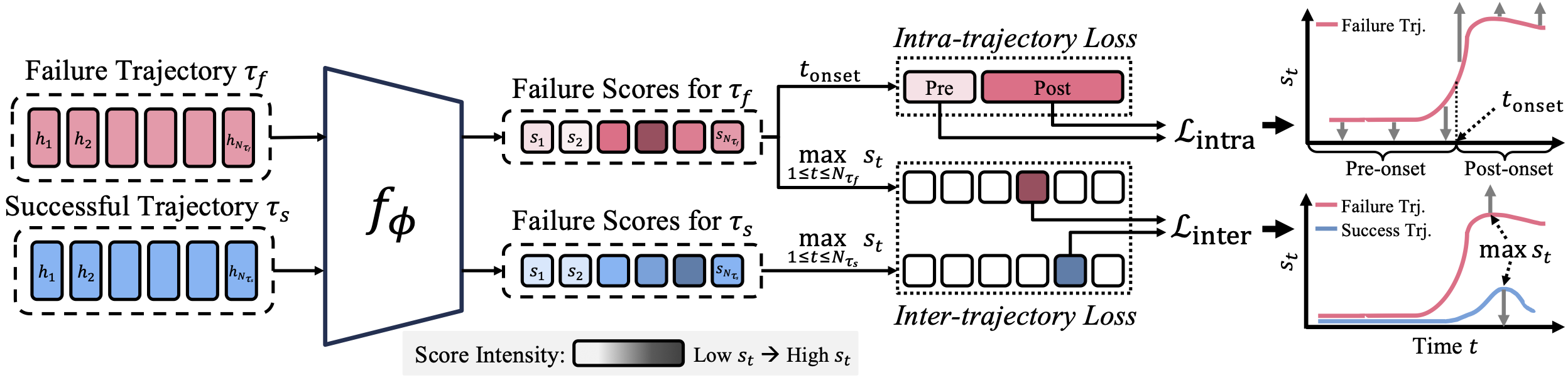
In this paper, we propose Hide-and-Seek, a framework that formulates VLA failure detection as a coarsely supervised learning problem.
By combining inter-trajectory and intra-trajectory contrastive objectives, Hide-and-Seek localizes failure-indicative actions and induces temporally structured failure signals from trajectory-level supervision alone, without any step-level annotation.
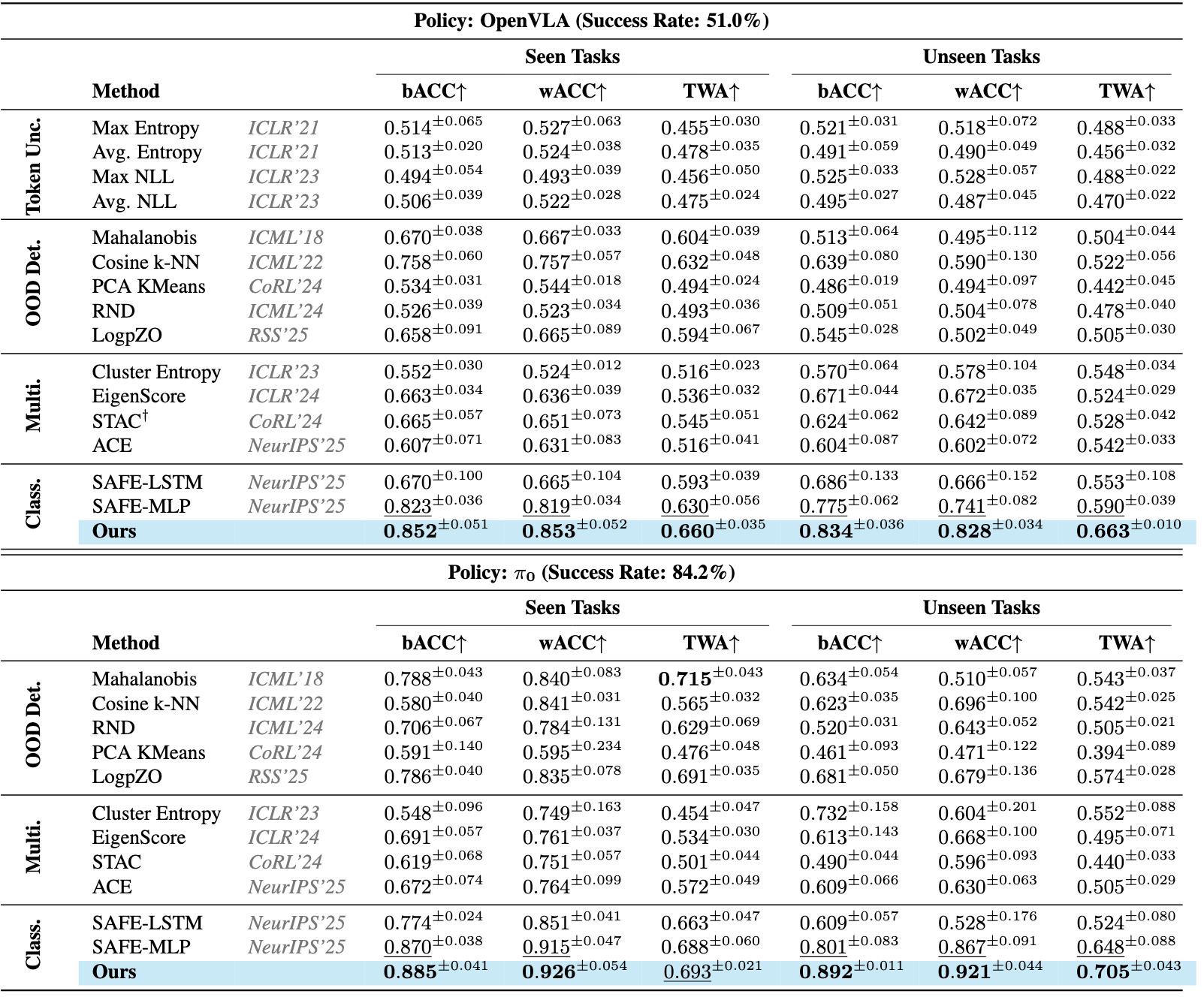
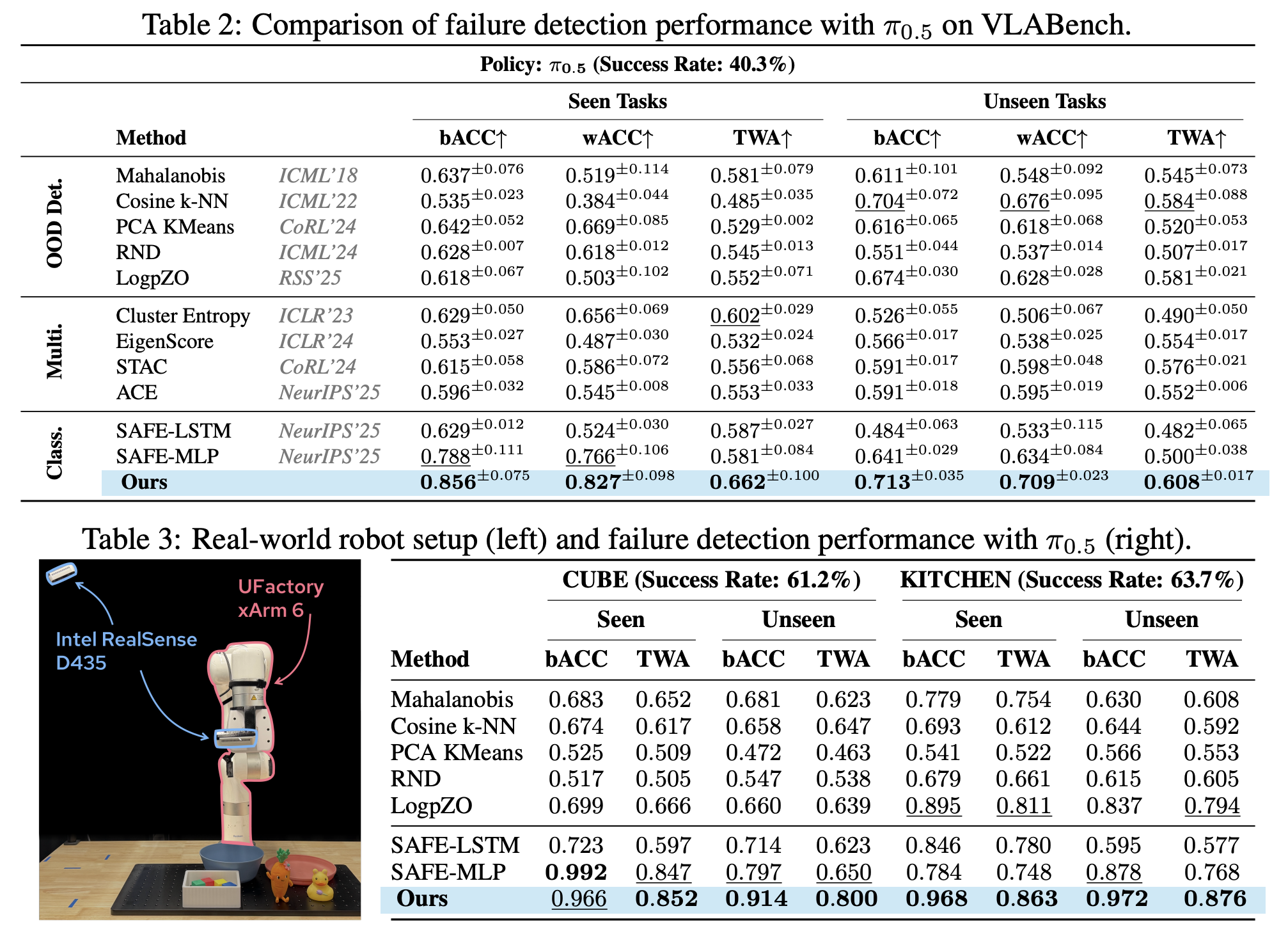
We evaluate Hide-and-Seek on LIBERO, VLABench, and a real-world robotic platform across three representative VLA policies: OpenVLA, π0, and π0.5.
Our method achieves state-of-the-art multi-task failure detection performance with a practical accuracy--timeliness trade-off under conformal prediction, and generalizes well to both seen and unseen tasks.